
Dynamic Novel View Synthesis aims to generate photorealistic views of moving subjects from arbitrary viewpoints. This task is particularly challenging when relying on monocular video, where disentangling structure from motion is ill-posed and supervision is scarce. We introduce Video Diffusion-Aware Reconstruction (ViDAR), a novel 4D reconstruction framework that leverages personalised diffusion models to synthesise a pseudo multi-view supervision signal for training a Gaussian splatting representation. By conditioning on scene-specific features, ViDAR recovers fine-grained appearance details while mitigating artefacts introduced by monocular ambiguity. To address the spatio-temporal inconsistency of diffusion-based supervision, we propose a diffusion-aware loss function and a camera pose optimisation strategy that aligns synthetic views with the underlying scene geometry. Experiments on DyCheck, a challenging benchmark with extreme viewpoint variation, show that ViDAR outperforms all state-of-the-art baselines in visual quality and geometric consistency. We further highlight ViDAR’s strong improvement over baselines on dynamic regions and provide a new benchmark to compare performance in reconstructing motion-rich parts of the scene.
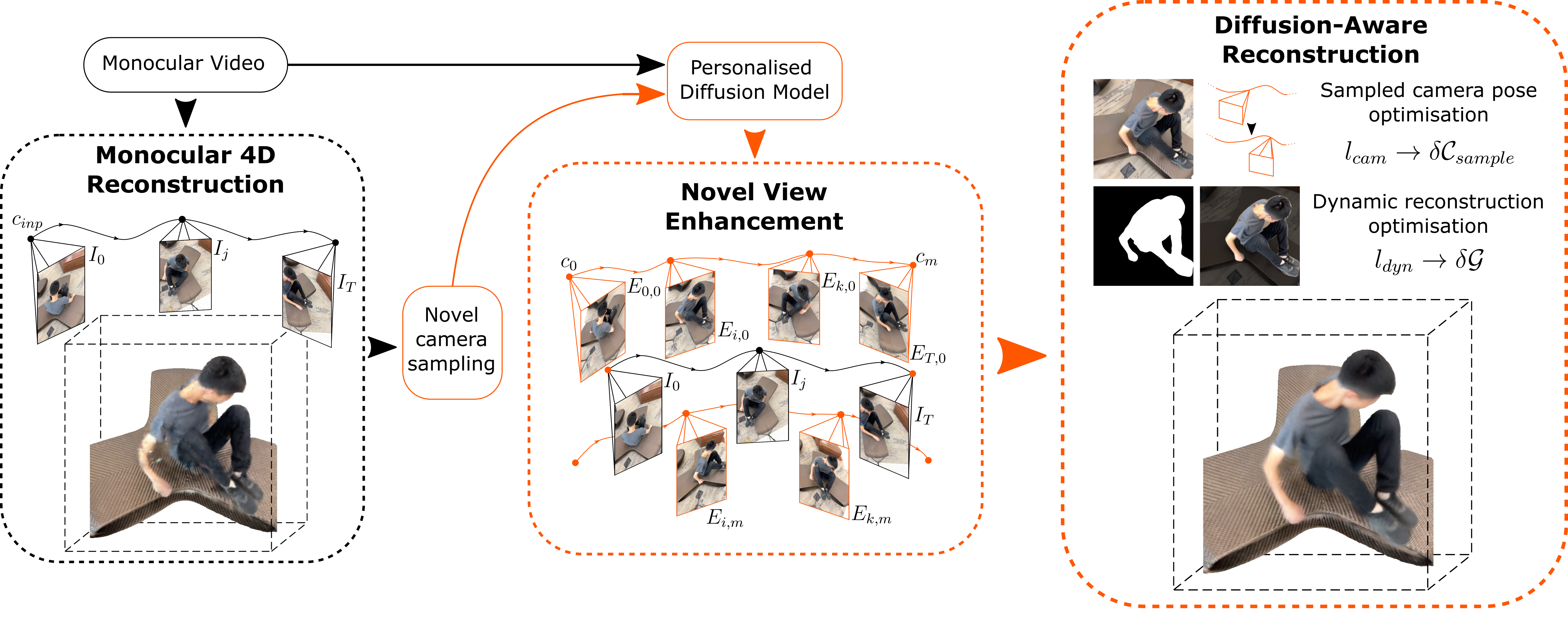
We first train a monocular reconstruction baseline and generate a set of typically degraded multi-view images by sampling diverse camera poses and rendering the novel viewpoints. We then adopt a DreamBooth-style personalisation strategy, and tailor a pretrained diffusion model to the input video, which we use as a generative enhancer to inject rich visual information back into the degraded renders. This effectively generates a set of high-fidelity pseudo-multi-view observations for our scene, although due to the nature of the diffusion process, the resulting images are not necessarily spatially consistent. We observe that naively using these views as supervision leads to reconstructions degraded by artefacts and geometric inconsistencies. To mitigate this, we propose a method of diffusion-aware reconstruction, which selectively applies diffusion-based guidance to dynamic regions of the scene while jointly optimising the camera poses associated with the diffused views.
Below we show qualitative results of state-of-the-art methods against ViDAR on DyCheck iPhone dataset. Videos are in full resolution, compressed for loading time.
MoSca
Ours
GT
MoSca
Ours
GT
MoSca
Ours
GT
MoSca
Ours
GT
Naive
Ours
GT
Naive
Ours
GT
Diffusion shows direct outputs of the personalised diffusion model. Naive corresponds to directly using diffusion outputs as supervision. -DR, -SO, and -TGS show the effects of removing Dynamic Reconstruction, Sampled Camera Optimisation, or Tracking Based Gaussian Classification, respectively.
@inproceedings{nazarczuk2025vidar,
author = {Nazarczuk, Michal and Catley-Chandar, Sibi and Tanay, Thomas and Zhang, Zhensong and Slabaugh, Gregory and Pérez-Pellitero, Eduardo},
title = {{ViDAR: Video Diffusion-Aware 4D Reconstruction From Monocular Inputs}},
booktitle = {Advances in Neural Information Processing Systems},
year = {2025},
}